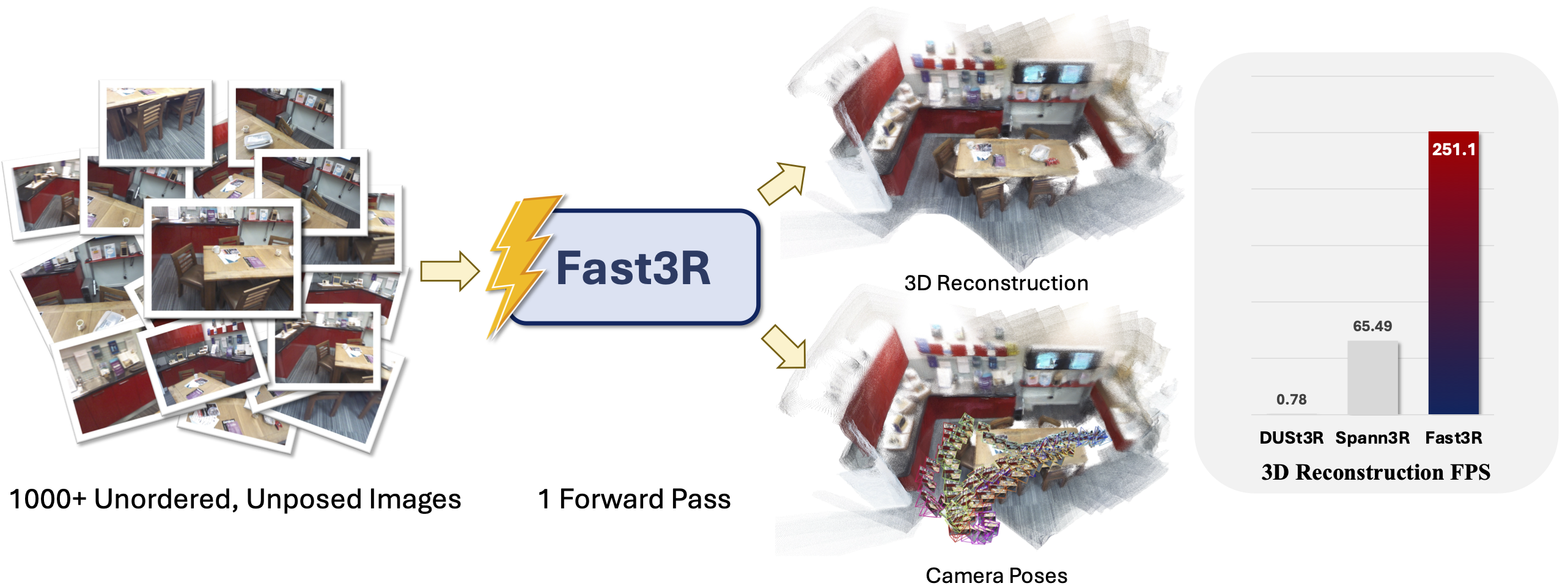
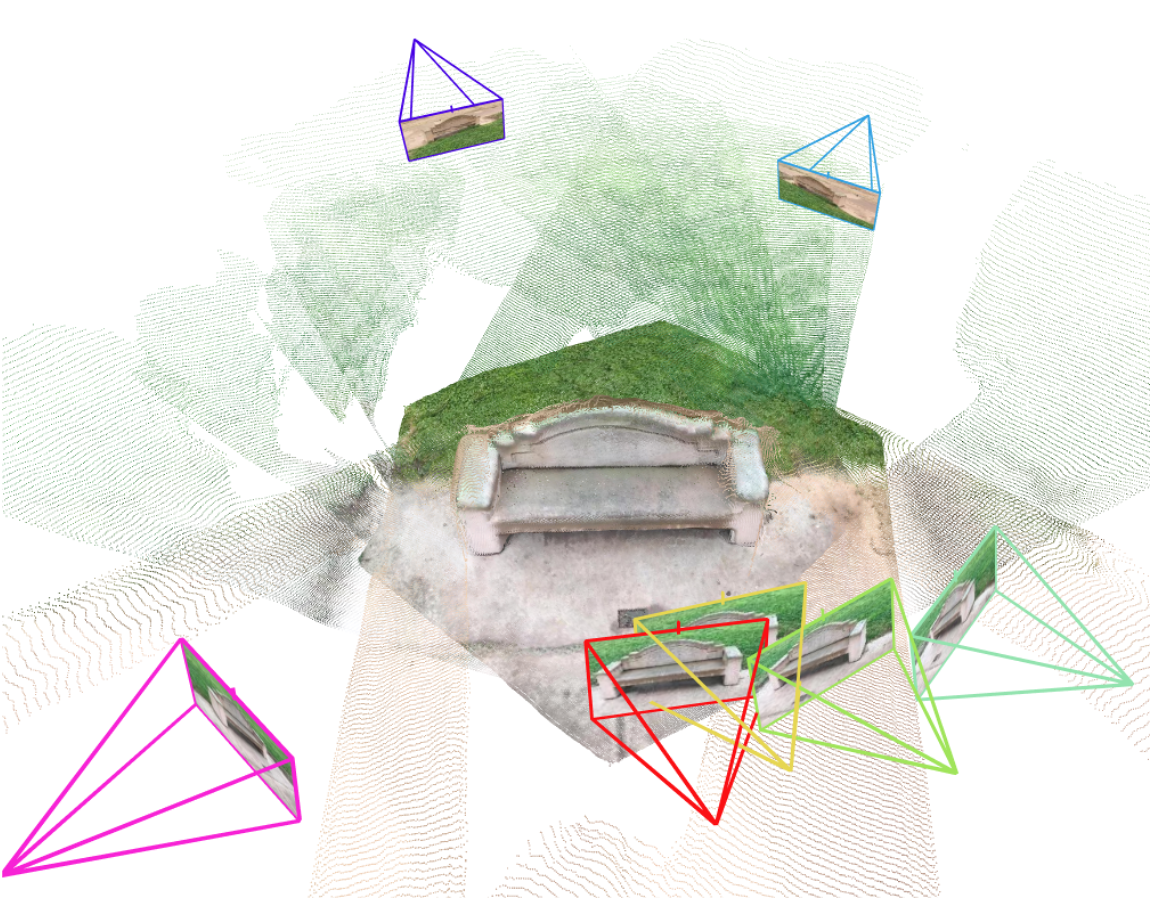
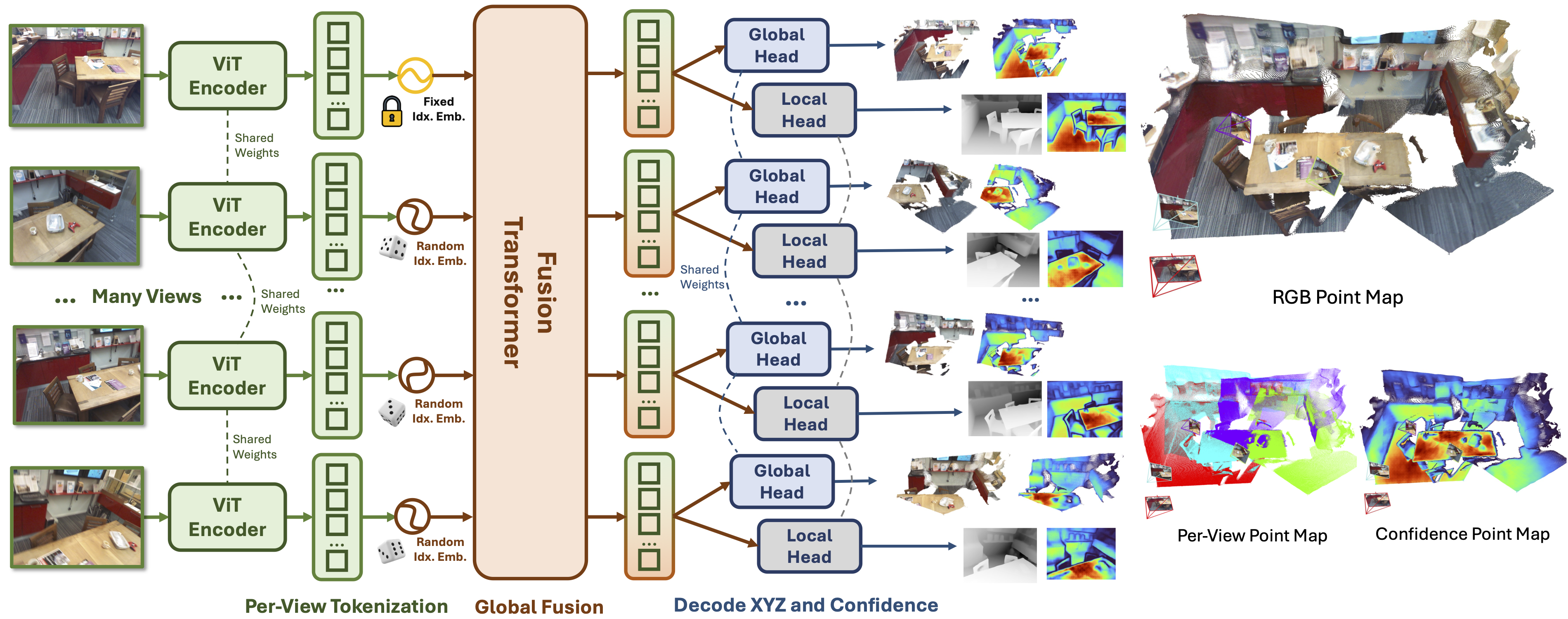
Multi-view 3D reconstruction remains a core challenge in
computer vision, particularly in applications requiring accurate
and scalable representations across diverse perspectives.
Current leading methods such as DUSt3R employ a fundamentally
pairwise approach, processing images in pairs and necessitating
costly global alignment procedures to reconstruct from multiple
views. In this work, we propose Fast
3D
Reconstruction (Fast3R),
a novel multi-view generalization to DUSt3R that achieves
efficient and scalable 3D reconstruction by processing many
views in parallel. Fast3R's Transformer-based architecture
forwards N images in a single forward pass, bypassing the need
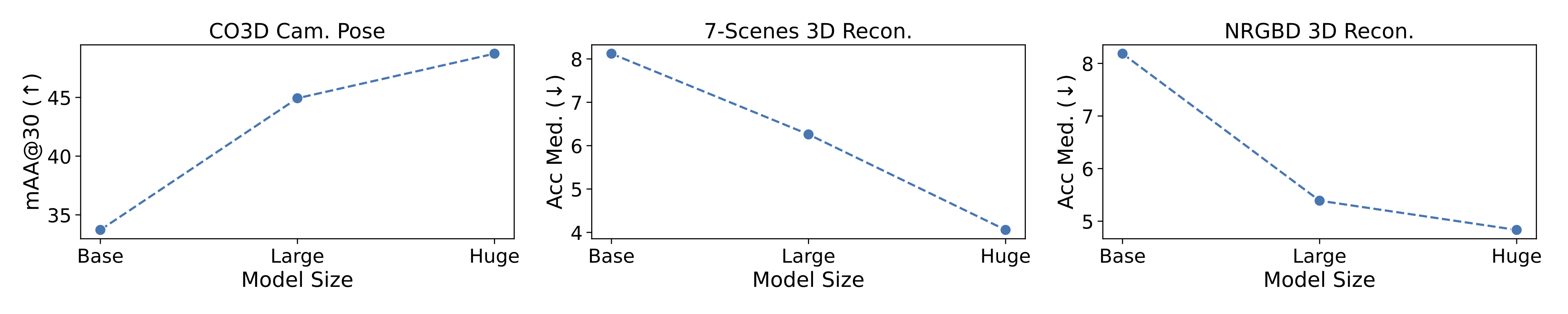
for iterative alignment. Through extensive experiments on camera
pose estimation and 3D reconstruction, Fast3R demonstrates
state-of-the-art performance, with significant improvements in
inference speed and reduced error accumulation. These results
establish Fast3R as a robust alternative for multi-view
applications, offering enhanced scalability without compromising
reconstruction accuracy.